
Wir bauen digitale Wege für das Servicegeschäft
Wir liefern passgenaue digitale Plattformen, die vor allem das Geschäft mit Aftermarket Services voranbringen.
Mit B2B Marktplätzen, Kundenportalen, Service-Plattformen, mobilen Apps und Industrial IoT-Lösungen
unterstützen wir die digitale Transformation im Maschinenbau.
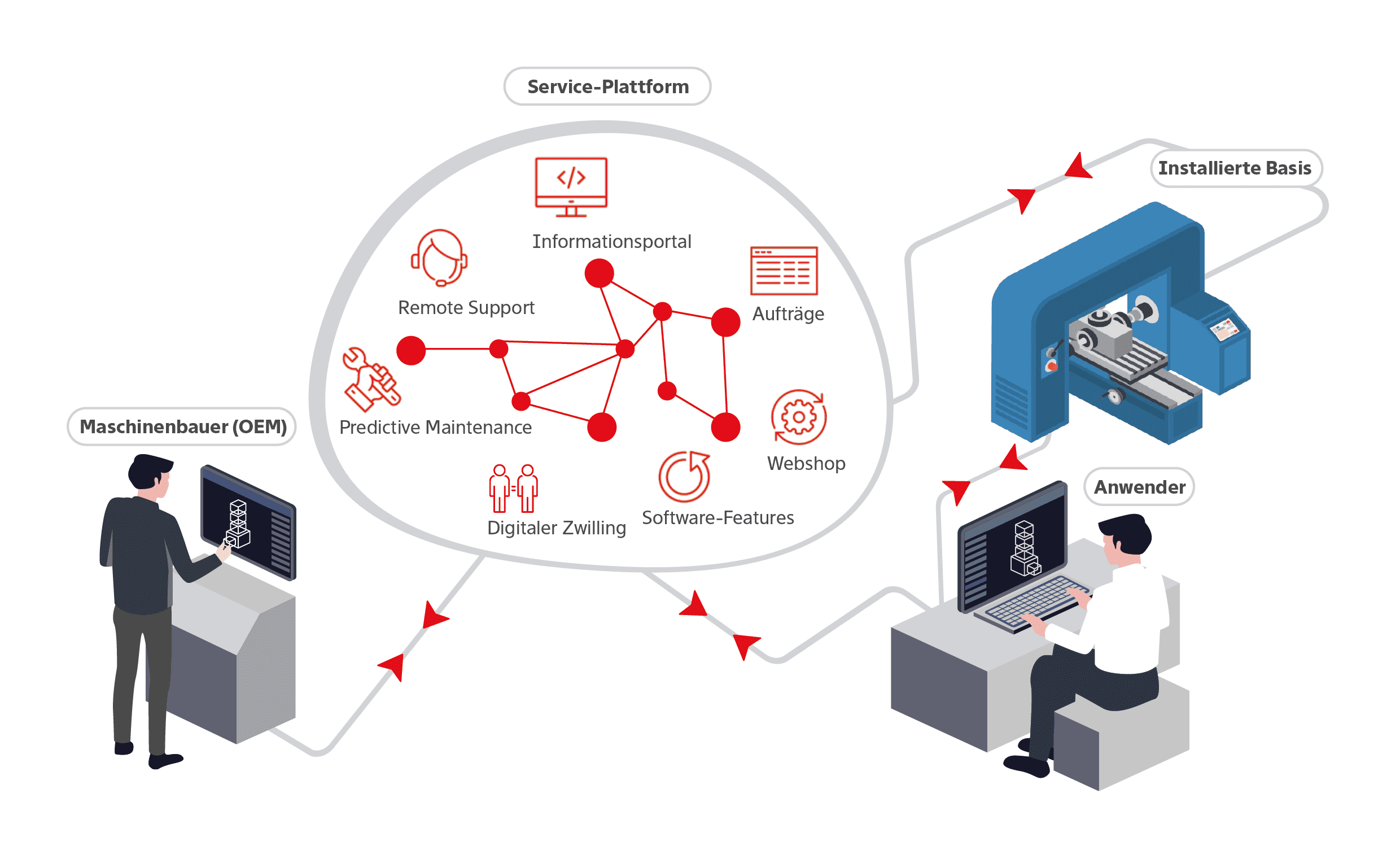
Digitale Aftermarket Services

Das Geschäft mit Aftermarket Services erfordert passgenaue digitale Plattformen. Von der smarten Maschine bis zum effizienten Service. Wir unterstützen Produkte und Prozesse im Maschinenbau und liefern voll integrierte und skalierbare Lösungen für Ihr digitales Geschäft.
Lösungen für höhere Kundenbindung

Eine höhere Kundenbindung und Effizienz im Service sind zentrale Anforderungen unserer Kunden. Unsere Lösungen dafür sind moderne Kundenportale, Ticketsysteme, mobile Apps, ein Industrial Asset Management, B2B Marktplätze und IIoT-Anwendungen.
Wegbereiter und Full Service Partner

Als Wegbereiter unterstützen wir die digitale Transformation im Maschinenbau. Wir denken lösungsorientiert und vom Kunden-Geschäft her, arbeiten agil und sind umsetzungsstark. Unsere Schlüsselkompetenzen sind Design, Entwicklung, Orchestrierung und Betrieb digitaler Plattformen.
Feedback unserer Kunden
“Die Reparametrisierung unserer Windkraftanlagen dauert heute nur noch wenige Minuten. Und das ist nur eins von vielen Beispielen, wie Nordex die mit logicline entwickelte IoT Plattform zur Effizienzsteigerung nutzt!”
“logicline ist für uns ein zuverlässiger Projektpartner und mit logicline’s Expertise mit der Salesforce Plattform konnten wir unser Projekt schnell und agil umsetzen.”
“logicline hat uns verstanden und gut beraten. Mit der Salesforce-Kompetenz konnten wir eine sehr schnelle Umsetzung sicherstellen und die App nach kurzer Zeit direkt beim Kunden einsetzen. Vielen Dank für den großartigen Einsatz!”
„Uns war es wichtig, einen verlässlichen Partner zu finden, mit dem wir auf lange Sicht zusammenarbeiten können.“
“Wir sind von der zielgerichteten und flexiblen Umsetzung durch logicline begeistert und sehen großes Potential in weiteren digitalen Angeboten für die Zukunft.”
“Die vielfältigen und komplexen Anforderungen an die App wurden dank logiclines Know-how erfolgreich erfüllt und der Security Review ohne Code-Probleme bestanden.”
“logicline verhalf uns schnell und schlank auf AppExchange – von der Idee und einem App-Konzept bis zum Security Review und dem Listing in AppExchange.”
“logicline hat uns in der Beratungsfunktion komplett überzeugt und hilft uns unsere Businessziele schneller zu erreichen.”
“logiclines Arbeitweise als Projekthaus ist schnell, agil und termingetreu mit einer Rundum-Betreuung über den ganzen Software-Lebenszyklus hinweg.”
„Unsere Erfahrung mit diesem Partner war unübertroffen! In den über 20 Jahren, in denen ich mit Implementierungspartnern […] zu tun hatte, hatte ich noch nie einen so hervorragenden Partner wie logicline. logicline hat die Messlatte ganz klar höher gelegt! […] Unsere Herausforderung war es, das Kundenerlebnis über unser Kundenportal auf ein völlig neues Level zu bringen und das „Netflix/Amazon“-Erlebnis zu bieten.“
News aus unserem Blog
Kundenportale: Mehr Wert für Maschinenbauer
Kundenportale: Zentrale Kommunikationsplattform und automatisiertes Asset-Management Ein leistungsfähiges Kundenportal ist die Basis für die Digitalisierung im Maschinen- und Anlagenbau. Hier einige Tipps zur Umsetzung. Der Maschinenbau befindet sich im Umbruch. Unternehmen müssen neben dem kurzfristigen Produktgeschäft längerfristige Umsatzströme erschließen. Damit rückt die installierte [...]

Machen Sie die installierte Basis zum Geschäftsmodell
Aktuelle Herausforderungen verlangen ein Update des Geschäftsmodells im Maschinenbau Die Industrie steht vor einigen Herausforderungen. Die 4 Megatrends Deglobalisierung, Demographie, Dekarbonisierung und Digitalisierung sind schon heute konkret im Geschäft spürbar. Dazu kommen weitere und steigende Anforderungen aus Regulierung (Lieferkettengesetz), Compliance (EU Data Act) [...]

Digitaler Zwilling – Was es ist und die Vorteile für Sie
Digitaler Zwilling - mehr Interoperabilität in der Industrie 4.0 Der Digitale Zwilling setzt neue Maßstäbe In der Ära der Industrie 4.0 haben sich viele neue Technologien und Konzepte entwickelt, die die Art und Weise, wie produziert und gearbeitet wird, revolutionieren. Eine solche Innovation, [...]

Ein Kundenportal: Für mehr Transparenz in der Auftragsabwicklung
Den Kundenservice verbessern Um den Bedürfnissen der Kunden heutzutage gerecht zu werden, ist es unumgänglich den Kundenservice zu verbessern. Dafür gibt es einige Stellschrauben, wie beispielsweise: die Omnichannel-Kommunikation, die personalisierte Interaktion, die proaktive Kommunikation, das effiziente Beschwerdemanagement, kontinuierliche Verbesserung durch Kunden-Feedback oder effiziente [...]

Mit Rapid IoT Design von der Idee zum validierten Business Case
Rapid IoT Design: Lösungen für das Internet der Dinge effizienter an den Markt bringen Das Internet der Dinge (IoT) hat in den letzten Jahren eine rasante Entwicklung erfahren und revolutioniert zahlreiche Branchen, von der Industrie bis hin zum Alltag der Verbraucher. Mit der [...]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}